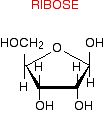
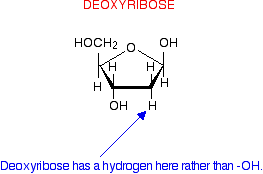
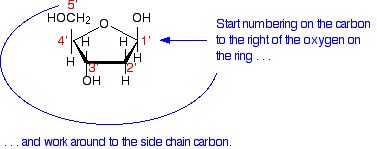
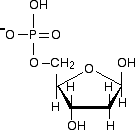
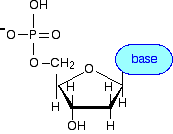
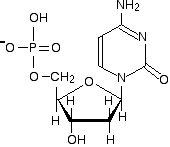
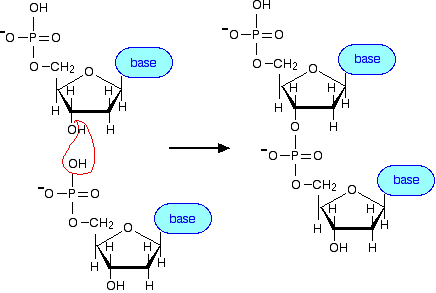
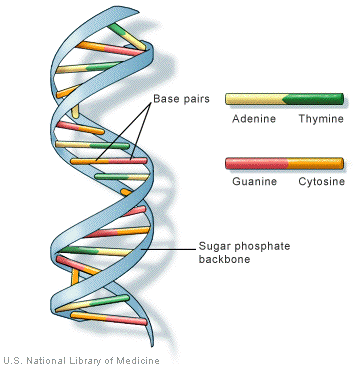
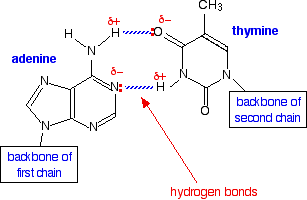
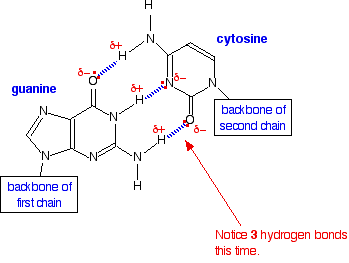
Most cellular RNA molecules are single stranded. They may form secondary structures such as stem-loop and hairpin.
Secondary structure of RNA. (a) stem-loop. (b) hairpin.
The major role of RNA is to participate in protein synthesis, which requires three classes of RNA:
Other classes of RNA include
Ribozymes
The RNA molecules with catalytic activity.
Small RNA molecules
RNA interference and other functions.
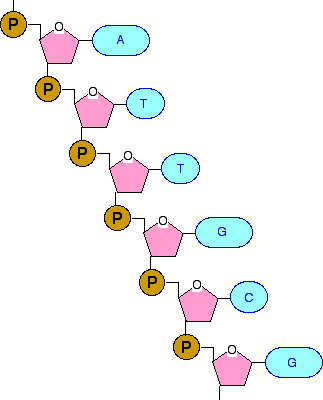
mRNA is transcribed from DNA, carrying information for protein synthesis. Three consecutive nucleotides in mRNA encode an amino acid or a stop signal for protein synthesis (see Genetic Code). The trinucleotide is know as a codon.

Figure 3-E-3. The sequence relationship of DNA, mRNA and the encoded peptide . The sequence of mRNA is complementary to DNA's template strand, and thus the same as DNA's coding strand, except that T is replaced by U.
Structure of tRNAThe major role of tRNA is to translate mRNA sequence into amino acid sequence. A tRNA molecule consists of 70-80 nucleotides. Its secondary and tertiary structures are shown in Figures 3-C-2 and 3-C-3, respectively. Some nucleotides in tRNA have been modified, such as dihydrouridine (D),pseudouridine (Y), and inosine (I). In dihydrouridine, a hydrogen atom is added to each C5 and C6 of uracil. In pseudouridine, the ribose is attached to C5, instead of the normal N1. Inosine plays an important role in codon recognition. In addition to these modifications, a few nucleosides are methylated.

Figure 3-C-2. The secondary structure of tRNA. Blue color indicates modified nucleotides, with "m" representing "methylated". Anticodon is the trinucleotides complementary to a codon on mRNA.

Figure 3-C-3. The tertiary structure of tRNA. PDB ID = 1TN2.
Ribosome
In prokaryotes, the ribosomal RNA (rRNA) has three types: 23S, 5S, and 16S. In mammals, four types of rRNA have been found : 28S, 5.8S, 5S and 18S. The unit "S" stands for Svedberg, which is a measure of the sedimentation rate. After rRNA molecules are produced in the nucleus, they are transported to the cytoplasm, where they combine with tens of specific proteins to form a ribosome. In prokaryotes, the size of a ribosome is 70S, consisting of two subunits: 50S and 30S. The size of a mammalian ribosome is 80S, comprising a 60S and a 40S subunit. Proteins in the larger subunit are designated as L1, L2, L3, etc. (L = large). In the smaller subunit, proteins are denoted by S1, S2, S3, etc.

Figure 3-C-4. The composition of ribosomes.
During protein synthesis, the ribosome binds to mRNA and tRNA as shown in the following figure. Only the tRNA containing the anticodon which matches mRNA's codon may join the complex.

Figure 3-C-5. The mRNA-ribosome-tRNA complex formed during protein synthesis.
Ribozyme
Ribozymes are the RNA molecules with catalytic activity. They were discovered in early 1980s by Thomas Cech and Sidney Altman who shared the 1989 Nobel Prize in Chemistry.
Small RNA Molecules
Major types of small RNA molecules:
- Small nuclear RNA (snRNA) - involved in mRNA splicing.
- Small nucleolar RNA (snoRNA) - directs the modification of ribosomal RNAs.
- Micro RNA (miRNA) and short interfering RNA (siRNA) - regulate gene expression.
Both miRNA and siRNA are about 20-25 nucleotides long. They are functionally equivalent, but differ in biogenesis. miRNAs are produced from transcripts that form stem-loop structures. In contrast, siRNAs are produced from long double-stranded RNA precursors (reference). These RNAs have been widely used in functional genomics and also have therapeutic potential.